
Setting Up Multi-Master Replication
In this replication topology, there are two master-slave relationships, with each table playing both the role of a master and a slave. Client applications update both tables and each table replicates updates to the other.
All updates from a source table arrive at a replica after having been authenticated at a gateway. Therefore, access control expressions on the replica that control permissions for updates to column families and columns are irrelevant; gateways have the implicit authority to update replicas.
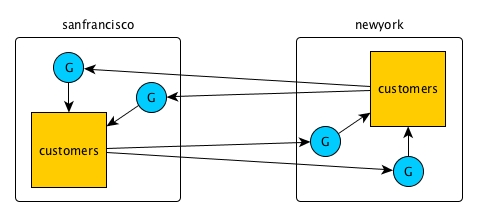
In this diagram, the customer table on the cluster
sanfrancisco replicates updates to the customers table
in the cluster newyork. The latter table in turn replicates updates to the
former table. MapR-DB tags each table operation with the universally unique ID (UUID) that
it has assigned the table at which the operation originated. Therefore, operations are
replicated only once and are not replicated back to the originating table.
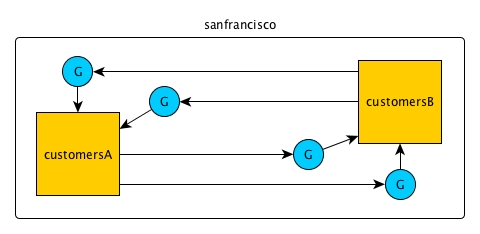
In this diagram, both tables are in a single cluster. Operations on table
customersA are replicated to table customersB and vice
versa.
Conflict Resolution
In the case of conflicting changes, MapR-DB compares the cell timestamps of the two changes. In the rare event that the cell timestamps are identical, MapR-DB compares the timestamps for when the changes arrived at their respective source tables. In the even rarer event that these latter timestamps are identical, MapR-DB uses the C library function memcmp to compare the data that is being modified by the conflicting changes, favoring the greater value.
Time-to-Live for Deletes
Normally, delete operations are purged after the affected table cells are updated. Whereas the result of an update is saved in a table until another change overwrites or deletes it, the result of a delete is not saved. In multi-master replication, this difference can lead to tables being unsynchronized.
Example Scenario to Illustrate Time-to-Live for Deletes
- On
/mapr/sanfrancisco/customers, put row A at 10:00:00 AM. - On
/mapr/newyork/customers, delete row A at 10:00:01 AM.
/mapr/sanfrancisco/customers, the order of operations is:- Put row A with a timestamp of 10:00:00 AM
- Delete row A with a timestamp of 10:00:01 AM (This operation is replicated from
/mapr/newyork/customers.)
/mapr/newyork/customers, the order of operations is:- Delete row A with a timestamp of 10:00:01 AM
- Put row A with a timestamp of 10:00:00 AM (This operation is replicated from
/mapr/sanfrancisco/customers.)
Now, though the put happened on /mapr/sanfrancisco/customers at
10:00:00 AM, the put reaches /mapr/newyork/customers several seconds
after that. Suppose that the actual time that the put arrives at
/mapr/newyork/customers is 10:00:03 AM.
To ensure that both tables stay synchronized, /mapr/newyork/customers
should preserve the delete until after the put is replicated. Then, the delete can be
applied after the put. Therefore, the time-to-live for the delete should be at least
long enough for the put to arrive at /mapr/newyork/customers. In this
case, the time-to-live should be at least 3 seconds.
In general, the time-to-live for deletes should be greater than the amount of time that
it takes replicated operations to reach replicas. By default, the value is 24 hours.
Configure the value with the -deletettl parameter in the
maprcli table edit command.
For example, suppose (to extend the scenario above) that you pause replication during
weekdays and resume it on weekends. The put takes place on Monday morning
/mapr/sanfrancisco/customers at 10:00:00 AM and the delete takes
place at /mapr/newyork/customers at 10:00:01 AM. Replication does not
resume until 12:00:00 AM Saturday morning. Given the volume of operations to be
replicated and the potential for network problems, it’s possible that these operations
will not be replicated until Sunday. In this scenario, a value of 7 days for
-deletettl (7 multiplied by 24 hours) should provide sufficient
margin.
Procedure
To set up this replication topology, follow one of these series of steps: