
Handling Disk Failures
When a disk fails, MapR raises the node-level alarm NODE_ALARM_DISK_FAILURE on
the node with the failed disk (or disks). At the same time, other disks in the same storage pool
as the failed disk are taken offline. You can look at the MapR Control System (MCS) and click on
Cluster>Dashboard to see a cluster heatmap of each node and a list of alarms, similar to
this:
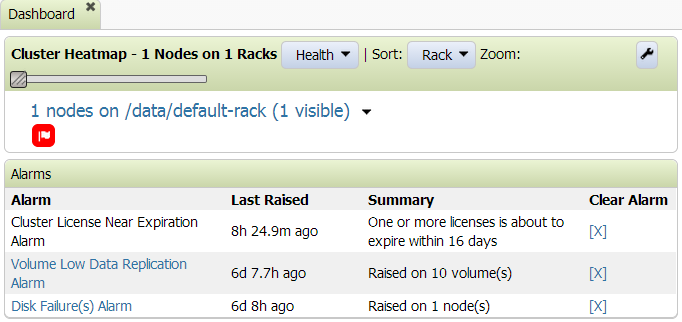
By hovering your mouse over the  , you can get more information about the reason for the failure. By
clicking on the , you can display node-specific information including an alarm summary
like the one below:
, you can get more information about the reason for the failure. By
clicking on the , you can display node-specific information including an alarm summary
like the one below:
, you can get more information about the reason for the failure. By
clicking on the , you can display node-specific information including an alarm summary
like the one below:When you see a disk failure alarm, examine the log file at
/opt/mapr/logs/faileddisk.log and check the Failure Reason field.