Mirroring Topics from the HPE Cluster to an Apache Kafka Cluster
You can use MirrorMaker to mirror data continuously from streams in HPE Ezmeral Data Fabric clusters to Apache Kafka clusters.
Prerequisites
- This procedure requires MirrorMaker to run from the HPE Ezmeral Data Fabric cluster. Verify that the mapr-kafka package is installed on the node that you choose to run MirrorMaker on.
- Configure the node as a
maprclient. - Ensure that the ID of the user who runs MirrorMaker has the
consumepermpermission on the stream.
About this task
After you start MirrorMaker, it launches a configurable number of consumer threads to read topics that are in a stream in a HPE Ezmeral Data Fabric cluster and a number of producers to write the messages from those topics into topics in an Apache Kafka cluster.
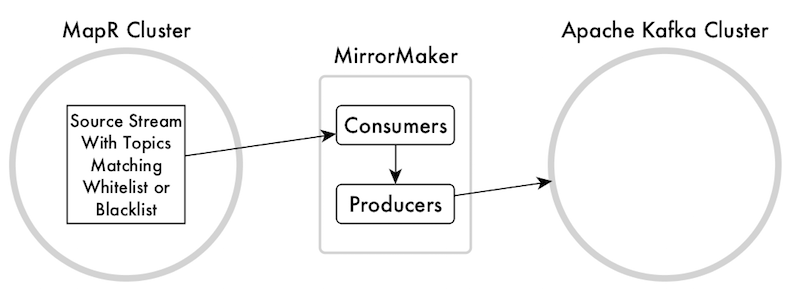
Before running MirrorMaker, you create a file that contains the required configuration parameters for the consumers that read from the stream in the HPE Ezmeral Data Fabric cluster. You also create a file that contains the required configuration parameters for the producers that publish to the Apache Kafka cluster. You point to these files in the MirrorMaker command.
To specify which topics you want to mirror, use the
whitelist parameter to provide a Java-style regular
expression that matches the names of the topics that you want mirrored.
Procedure
-
Create a file that contains the required properties and values for consumers to
use. When you run MirrorMaker, you point to this file by using the
consumer.configparameter.Property Description streams.record.strip.streampathSet the value of this property to true. In messages that are written to streams, the names of topics include the paths and names of the streams in which those topics are located. Apache Kafka needs only the names of the topics. This parameter removes the path and name of the stream that the topics will be mirrored from. streams.consumer.default.streamSpecifies the path and name of the stream that the topics will be mirrored from. group.idA unique string that identifies the consumer group the consumers started by MirroMaker belong to. -
Create a file that contains the required properties and values for producers to
use. When you run MirrorMaker, you point to this file by using the
producer.configparameter.Property Description bootstrap.serversA list of host/port pairs to use for establishing the initial connection to the Kafka cluster. The producers will make use of all servers irrespective of which servers are specified here for bootstrapping—this list only impacts the initial hosts used to discover the full set of servers. This list should be in the form host1:port1,host2:port2,.... Since these servers are just used for the initial connection to discover the full cluster membership (which may change dynamically), this list need not contain the full set of servers (you may want more than one, though, in case a server is down).producer.typeSpecifies whether the messages are published asynchronously in batches or as data is received by producers. The values are asyncandsync.compression.codecSpecifies the compression codec for all messages that are generated by producers. The possible values are none,gzip,snappy, andlz4. -
Run MirrorMaker with this command to start mirroring topics from HPE Ezmeral Data Fabric Streams
to Apache Kafka:
Syntax
bin/kafka-mirror-maker.sh --consumer.config <File that lists consumer properties and values> --num.streams <Number of consumer threads> --producer.config <File that lists producer properties and values> --whitelist=<Java-style regular expression for specifying the topics to mirror>Parameter Description consumer.configThe path and name of the file that lists the consumer properties and their values. new.consumerSpecifies to use consumers that use the Apache Kafka 0.90 API library. num.streamsUse this parameter to specify the number of mirror consumer threads to create. Note that if you start multiple mirror maker processes then you may want to look at the distribution of partitions on the source cluster. If the number of consumption streams is too high per mirror maker process, then some of the mirroring threads will be idle by virtue of the consumer rebalancing algorithm (if they do not end up owning any partitions for consumption). producer.configThe path and name of the file that lists the producer properties and their values. whitelistA Java-style regular expression for specifying the topics to copy. Commas (',') are interpreted as the regex-choice symbol ('|'). This parameter is required.
Example
In this example, the file that lists the properties and values for the consumer that
will read messages from the topics in HPE Ezmeral Data Fabric Streams is named
consumers.props. It contains this list:
streams.record.strip.streampath=true
streams.consumer.default.stream=/myStream
group.id=cg1The file that lists the properties and values for the producers that will publish
messages to topics in Apache Kafka is named producers.props. It
contains this list:
bootstrap.servers =10.10.83.93:9092
producer.type=sync
compression.codec=noneThe topics to mirror all have names that begin with na_west. When
running the command, we can use "na_west.*" as the regular
expression to use for the whitelist parameter.
bin/kafka-mirror-maker.sh --new.consumer
--consumer.config consumers.props --num.streams 2 --producer.config producers.props
--whitelist="na_west.*"