7.6.1 Data Fabric
HPE Ezmeral Data Fabric is the industry-leading data platform for AI and analytics that solves enterprise business needs.
-
Speed up AI and analytics initiatives for more impact at production scale
-
Accelerate time-to-value for hybrid cloud and multi-cloud strategies
-
Create highly reliable, scalable data fabric
-
Use data streams for real-time edge analytics
-
Implement Kubernetes containerization more effectively
The HPE Ezmeral Data Fabric allows you to address your critical data needs while providing industry-leading performance, data security, easy application development, and true scalability.
The HPE Ezmeral Data Fabric enables you to solve critical business needs:
| Business Need | HPE Ezmeral Data Fabric Provides.... | Typical Use Cases... |
|---|---|---|
| AI and Analytics | A data platform approach for a full range of AI, ML, Analytics with no silos, faster response, and mission-critical reliability at scale |
|
| IOT and Edge Analytic | Seamless edge to on-prem or cloud data movement with analytics |
|
| Journey to Cloud | Easy data and application movement between on-prem and multiple clouds delivers lower TCO and higher flexibility |
|
| Containers | Enable stateful applications in containers to use system-of-record data in a high-reliability platform |
|
High-Level View of the HPE Ezmeral Data Fabric
The following diagram shows the basic components of the HPE Ezmeral Data Fabric.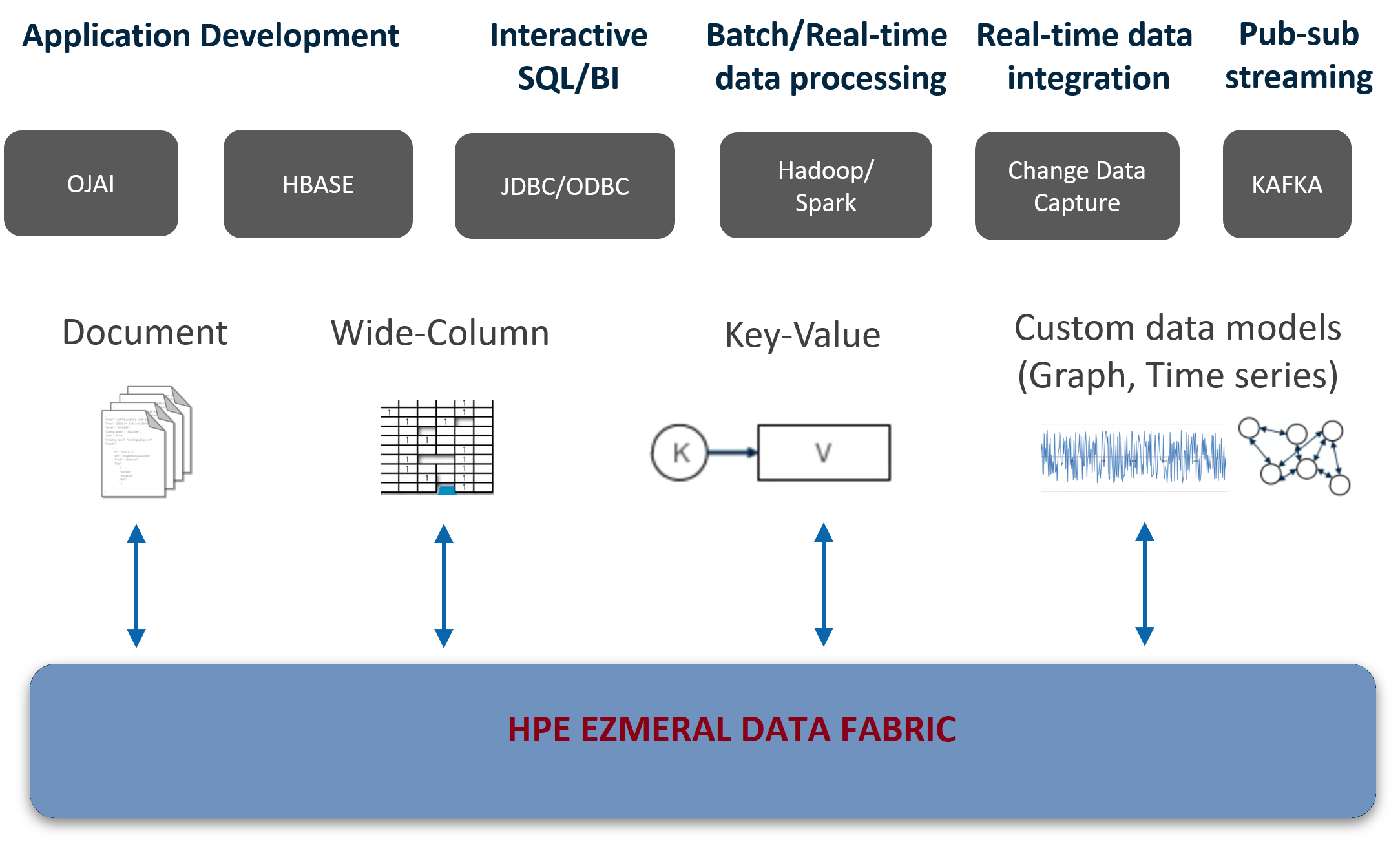
Getting Started
To learn more about HPE Ezmeral Data Fabric, see this course.
Learn More about the Architecture of the HPE Ezmeral Data Fabric Components
This system overview contains architectural details about the components that run on the HPE Ezmeral Data Fabric and the relationships between the components. See these topics to learn about each component.Additional Resources
For an introduction to how a data fabric can help enable a comprehensive data strategy, see this blog.