Direct Shuffle on YARN
Explains the shuffle phase of a MapReduce application.
Overview of Direct Shuffle
During the shuffle phase of a MapReduce application, HPE Ezmeral Data Fabric writes to a file system volume limited by its topology to the local node instead of writing intermediate data to local disks controlled by the operating system. This improves performance and reduces demand on local disk space while making the output available cluster-wide.
Direct Shuffle is the default shuffle mechanism for HPE Ezmeral Data Fabric. However, you can modify the
yarn-site.xml and mapred-site.xml configuration files to
enable Apache Shuffle for MapReduce applications. See Apache Shuffle on YARN.
The LocalVolumeAuxiliaryService runs in the NodeManager process. The LocalVolumeAuxiliaryService manages the local volume on each node and cleans up shuffle data after a MapReduce application has finished executing.
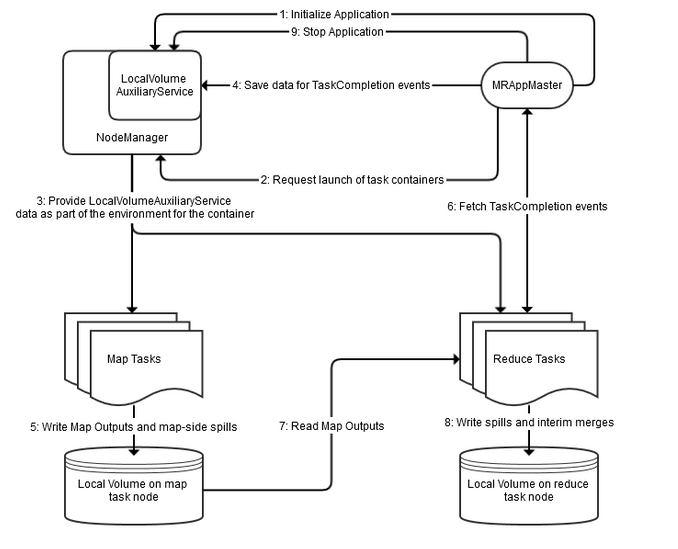
- The MRAppMaster service initializes the application by calling
initializeApplication()on the LocalVolumeAuxiliaryService. - The MRAppMaster service requests task containers from the ResourceManager. The ResourceManager sends the MRAppMaster information that MRAppMaster uses to request containers from the NodeManager.
- The NodeManager on each node launches containers using information about the node’s local volume from the LocalVolumeAuxiliaryService.
- Data from map tasks is saved in MRAppMaster for later use in TaskCompletion events, which are requested by reduce tasks.
- As map tasks complete, map outputs and map-side spills are written to the local volumes on the map task nodes, generating Task Completion events.
- ReduceTasks fetch Task Completion events from the Application Manager. The task Completion events include information on the location of map output data, enabling reduce tasks to copy data from MapOutput locations.
- Reduce tasks read the map output information.
- Spills and interim merges are written to local volumes on the reduce task nodes.
- MRAppMaster calls
stopApplication()on the LocalVolumeAuxiliaryService to clean up data on the local volume.
Configuration for Direct Shuffle
The deafult YARN parameters for Direct Shuffle are as follows:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,mapr_direct_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapr_direct_shuffle.class</name>
<value>org.apache.hadoop.mapred.LocalVolumeAuxService</value>
</property>The default mapred parameters for Direct Shuffle are as follows:
<property>
<name>mapreduce.job.shuffle.provider.services</name>
<value>mapr_direct_shuffle</value>
</property>
<property>
<name>mapreduce.job.reduce.shuffle.consumer.plugin.class</name>
<value>org.apache.hadoop.mapreduce.task.reduce.DirectShuffle</value>
</property>
<property>
<name>mapreduce.job.map.output.collector.class</name>
<value>org.apache.hadoop.mapred.MapRFsOutputBuffer</value>
</property>
<property>
<name>mapred.ifile.outputstream</name>
<value>org.apache.hadoop.mapred.MapRIFileOutputStream</value>
</property>
<property>
<name>mapred.ifile.inputstream</name>
<value>org.apache.hadoop.mapred.MapRIFileInputStream</value>
</property>
<property>
<name>mapred.local.mapoutput</name>
<value>false</value>
</property>
<property>
<name>mapreduce.task.local.output.class</name>
<value>org.apache.hadoop.mapred.MapRFsOutputFile</value>
</property>