HPE Ezmeral Data Fabric Database and Apps
This section contains information about developing client applications for JSON and key-value tables.
Why use HPE Ezmeral Data Fabric Database?
From a developer's point-of-view, HPE Ezmeral Data Fabric Database provides the following capabilities:
- Extreme scale for CRUD operations: Enabled by the integration of HPE Ezmeral Data Fabric Database with the HPE Ezmeral Data Fabric Filesystem, CRUD operations are extremely fast and efficient.
- Flexible data model: HPE Ezmeral Data Fabric Database can be used as both a document database and a column-oriented database. So if the content structure changes, the applications do not need to be re-written.
- Rich query: Integration with Apache Drill for HPE Ezmeral Data Fabric Database provides a low-latency distributed query engine for large-scale datasets, including structured and semi-structured/nested data.
- Integration with Apache Spark: HPE Ezmeral Data Fabric Database provides HPE Ezmeral Data Fabric Database Connectors for Apache Spark that allow you to access HPE Ezmeral Data Fabric Database tables through Spark applications.
- Strong data consistency: Consistently fast response with strong data consistency with row/document level ACID transactions and in-memory database options for faster speeds.
HPE Ezmeral Data Fabric Database JSON provides additional benefits:
- High performance via Secondary Indexes: No memory copying. No need to retrieve the full document to make updates due the log-based database architecture. No application changes needed to leverage secondary indexes for efficient query execution.
- Easy application development: JSON constructs such as maps, arrays, and data types are supported natively.
- Language-specific client APIs: Java, Python, and Node.js client APIs
How Do I Get Started with HPE Ezmeral Data Fabric Database JSON?
The following diagram illustrates an end-to-end flow associated with getting started with HPE Ezmeral Data Fabric Database JSON.
- Container for Developers
-
Development Environment for HPE Ezmeral Data Fabric is a Docker container that runs a single node cluster. Using HPE Ezmeral Data Fabric Database JSON: Getting Started, you can do the following:
- Set up the Docker container
- Import data into HPE Ezmeral Data Fabric Database JSON tables
- Use HPE Ezmeral Data Fabric Database Shell to query, insert, and update JSON documents in HPE Ezmeral Data Fabric Database JSON tables
- Use Drill to query HPE Ezmeral Data Fabric Database JSON tables
- Run sample Java OJAI applications
- Run a sample Spark application using the HPE Ezmeral Data Fabric Database OJAI Connector for Apache Spark
Useful HPE Ezmeral Data Fabric Database JSON Developer Resources
| Getting Started and Examples | Tools, Utilities, and Applications | General (Blogs, etc) | API Details |
|---|---|---|---|
| Managing JSON Tables - Examples creating, listing, and deleting HPE Ezmeral Data Fabric Database JSON tables | maprcli and REST API Syntax | Data Modeling Guidelines for NoSQL JSON Document Databases |
HPE Ezmeral Data Fabric Database JSON Client API NOTE Beginning with core version 6.0,
the HPE Ezmeral Data Fabric Database
Table interface in the HPE Ezmeral Data Fabric Database JSON Client API is deprecated
and replaced by the DocumentStore interface in
the OJAI API library. See the next row for details on that
API. |
| Managing JSON Documents - Examples performing CRUD operations on JSON documents in HPE Ezmeral Data Fabric Database JSON tables | Utilities for HPE Ezmeral Data Fabric Database JSON Tables | App development with OJAI | Java OJAI Client API |
| Querying JSON Documents - Examples querying JSON documents in HPE Ezmeral Data Fabric Database JSON tables | Apache Drill | How to Build Applications on a NoSQL Document Database and Perform Analytics in Place | Node.js OJAI Client API |
| Getting Started with the HPE Ezmeral Data Fabric Database JSON REST API | Understanding the HPE Ezmeral Data Fabric Database OJAI Connector for Spark | Python OJAI Client API | |
| Getting Started with the Node.js OJAI Client | |||
| Getting Started with the Python OJAI Client | |||
| Tutorials - Instructions and code to build a sample web application using HPE Ezmeral Data Fabric Database JSON |
How Do I Get Started with HPE Ezmeral Data Fabric Database Binary?
The following diagram illustrates an end-to-end flow associated with getting started with HPE Ezmeral Data Fabric Database Binary.
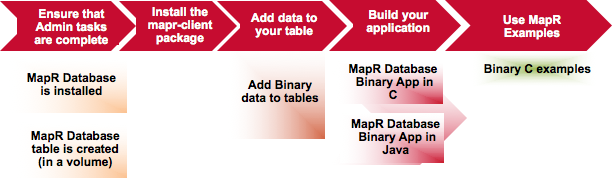
Useful HPE Ezmeral Data Fabric Database Binary Developer Resources
| Getting Started and Examples | Tools, Utilities, and Applications | General (Blogs, etc) |
|---|---|---|
| HPE Ezmeral Data Fabric Database Sample C Application - C application example for binary tables | maprcli and REST API Syntax | High Performance C APIS on HPE Ezmeral Data Fabric Database |
| Utilities for HPE Ezmeral Data Fabric Database Binary Tables | ||
| Apache Drill | ||
| HPE Ezmeral Data Fabric Database Binary Connector for Apache Spark |