HCatalog
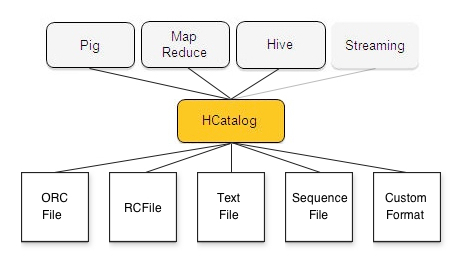
HCatalog is a table and storage management layer for Hadoop that enables users with different data processing tools — Pig, MapReduce — to more easily read and write data on the grid. HCatalog’s table abstraction presents users with a relational view of data in the Hadoop distributed filesystem (HDFS) and ensures that users need not worry about where or in what format their data is stored — RCFile format, text files, SequenceFiles, or ORC files.
HCatalog supports reading and writing files in any format for which a SerDe (serializer-deserializer) can be written. By default, HCatalog supports RCFile, CSV, JSON, and SequenceFile, and ORC file formats. To use a custom format, you must provide the InputFormat, OutputFormat, and SerDe.
HCatalog is also automatically installed and upgraded along with Hive. For information about using HCatalog with Hive, see Hive and WebHCat Integration and Hive and HCatalog Integration.